
فایل robots.txt، یک ابزار حیاتی در دنیای سئو است که میتواند تأثیر بسزایی در عملکرد وبسایت شما داشته باشد. این فایل، راهنماییهای لازم را به خزندههای موتورهای جستجو ارائه میدهد و به شما امکان میدهد تا کنترل دقیقی بر نحوه ایندکس شدن صفحات وبسایتتان داشته باشید. با استفاده صحیح از robots.txt، میتوانید از ایندکس شدن محتوای تکراری جلوگیری کنید، بودجه خزش (crawl budget) را بهینه کنید و صفحات مهم خود را در معرض دید موتورهای جستجو قرار دهید. در این مقاله، به بررسی جامع این فایل، از چیستی تا نحوه ساخت و ترفندهای بهینهسازی آن میپردازیم.
با ما همراه باشید تا با دنیای robots.txt آشنا شوید.
Robots.txt چیست؟
فایل robots.txt، یک فایل متنی است که در ریشه (root) وبسایت شما قرار میگیرد و به رباتهای موتورهای جستجو (مانند گوگل) دستورالعملهایی را ارائه میدهد. این دستورالعملها مشخص میکنند که کدام بخشها یا صفحات وبسایت باید توسط رباتها بررسی و ایندکس شوند و کدام بخشها نباید. به عبارت دیگر، robots.txt نقش یک نگهبان را دارد که به رباتها اجازه ورود به بخشهای خاصی از وبسایت شما را میدهد و از ورود آنها به بخشهای دیگر جلوگیری میکند. استفاده صحیح از این فایل، میتواند تأثیر چشمگیری بر سئو و بهینهسازی وبسایت شما داشته باشد.
نکته مهم: اگرچه اکثر موتورهای جستجو از دستورات robots.txt پیروی میکنند، اما این تضمینی نیست که همه آنها این کار را انجام دهند. با این حال، گوگل به عنوان بزرگترین موتور جستجو، به دستورالعملهای این فایل احترام میگذارد.
موقعیت فایل Robots.txt در وبسایت
فایل robots.txt باید در ریشه اصلی دامنه وبسایت شما قرار داشته باشد. برای مثال، اگر آدرس وبسایت شما www.example.com است، فایل robots.txt باید در آدرس www.example.com/robots.txt قابل دسترسی باشد. برای بررسی وجود این فایل، کافی است این آدرس را در مرورگر خود وارد کنید. اگر فایل robots.txt در آنجا وجود داشته باشد، محتوای آن را مشاهده خواهید کرد. در غیر این صورت، میتوانید با دنبال کردن آموزشهای این مقاله، آن را ایجاد کنید.
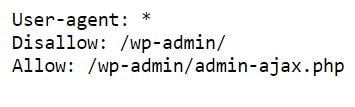
ساختار فایل Robots.txt
ساختار فایل robots.txt بسیار ساده است و از دستورات مختلفی برای هدایت رباتهای موتورهای جستجو استفاده میکند. در اینجا، فرمت کلی این فایل را مشاهده میکنید:
User-agent: [نام ربات] Disallow: [مسیر یا آدرس مورد نظر] Allow: [مسیر یا آدرس مجاز (اختیاری)] Sitemap: [آدرس نقشه سایت (اختیاری)]
در ادامه، به بررسی هر یک از این بخشها و دستورات میپردازیم.
User-agents: شناسایی رباتها
User-agent، شناسه رباتهای مختلف موتورهای جستجو است. هر موتور جستجو، رباتهای مختلفی دارد که وظیفه بررسی و ایندکس کردن صفحات وب را بر عهده دارند. در فایل robots.txt، شما میتوانید دستورالعملهای متفاوتی را برای هر User-agent تعریف کنید. در اینجا، لیستی از User-agents مهم را مشاهده میکنید:
- Googlebot: ربات اصلی گوگل
- Googlebot-Image: ربات تصاویر گوگل
- Bingbot: ربات بینگ
- Slurp: ربات یاهو
- Baiduspider: ربات بایدو
- DuckDuckBot: ربات DuckDuckGo
نکته مهم: نام User-agents به حروف بزرگ و کوچک حساس است. بنابراین، هنگام نوشتن نام آنها در فایل robots.txt، باید به این موضوع توجه کنید.
اگر میخواهید یک دستورالعمل را برای همه رباتها اعمال کنید، میتوانید از علامت ستاره (*) استفاده کنید. به عنوان مثال، اگر میخواهید دسترسی همه رباتها به جز گوگل را مسدود کنید، میتوانید از کد زیر استفاده کنید:
User-agent: * Disallow: / User-agent: Googlebot Allow: /
به یاد داشته باشید که هر User-agent باید به صورت جداگانه تعریف شود. اگر برای یک User-agent، چند دستور مختلف تعریف کنید، همه آنها با هم اعمال میشوند.
Directives: دستورالعملهای اصلی در Robots.txt
Directives، دستورالعملهایی هستند که برای هر User-agent تعریف میشوند و به رباتها میگویند که چه کاری انجام دهند. در اینجا، به بررسی مهمترین Directives میپردازیم:
-
Disallow: مسدود کردن دسترسی
دستور Disallow، برای مسدود کردن دسترسی رباتها به صفحات یا فایلهای خاصی استفاده میشود. به عنوان مثال، اگر میخواهید دسترسی رباتها به پوشه /blog را مسدود کنید، باید از کد زیر استفاده کنید:
User-agent: * Disallow: /blog
توجه: اگر آدرس بعد از Disallow را به درستی وارد نکنید، این دستور توسط موتورهای جستجو نادیده گرفته خواهد شد.
-
Allow: اجازه دسترسی
دستور Allow، برای اجازه دادن به دسترسی رباتها به صفحات یا زیرشاخههای خاصی استفاده میشود، حتی اگر آن صفحه یا زیرشاخه در یک دایرکتوری مسدود شده (با استفاده از Disallow) قرار داشته باشد. این دستور توسط گوگل و بینگ پشتیبانی میشود. به عنوان مثال، اگر میخواهید دسترسی رباتها به تمام صفحات پوشه /blog مسدود شود، به جز یک صفحه خاص، میتوانید از کد زیر استفاده کنید:
User-agent: * Disallow: /blog Allow: /blog/allowed-post
در این مثال، allowed-post، نام صفحه مورد نظر شما در پوشه /blog است.
توجه: اگر آدرس بعد از Allow را به درستی وارد نکنید، این دستور توسط موتورهای جستجو نادیده گرفته خواهد شد.
هنگام استفاده از دستورات Disallow و Allow، باید دقت کنید که تضادی بین آنها ایجاد نشود. اگر چنین اتفاقی بیفتد، گوگل و بینگ معمولاً دستوری را اجرا میکنند که تعداد کاراکترهای بیشتری داشته باشد. اگر تعداد کاراکترها برابر باشد، دستوری که آخر از همه آمده است، اجرا میشود. سایر موتورهای جستجو ممکن است از این قوانین پیروی نکنند و دستور اول را در اولویت قرار دهند.
Sitemap: معرفی نقشه سایت
دستور Sitemap، برای معرفی نقشه سایت به موتورهای جستجو استفاده میشود. نقشه سایت، فایلی است که شامل لیستی از تمام صفحات مهم وبسایت شما است که میخواهید توسط موتورهای جستجو بررسی و ایندکس شوند. با معرفی نقشه سایت به موتورهای جستجو، میتوانید به آنها کمک کنید تا صفحات وبسایت شما را سریعتر و بهتر پیدا کنند.
Sitemap: https://www.example.com/sitemap.xml
اگر نقشه سایت خود را از طریق ابزارهایی مانند Google Search Console به گوگل معرفی کردهاید، نیازی به این دستور ندارید. با این حال، برای سایر موتورهای جستجو (مانند بینگ)، استفاده از این دستور توصیه میشود. این دستور را باید در ابتدای فایل robots.txt قرار دهید.
دستوراتی که نباید در Robots.txt استفاده کنید
برخی از دستورات، دیگر توسط گوگل پشتیبانی نمیشوند و استفاده از آنها در فایل robots.txt توصیه نمیشود. در اینجا، به بررسی این دستورات میپردازیم:
-
Crawl-delay
دستور Crawl-delay، برای تعیین تأخیر زمانی بین خزش رباتها استفاده میشود. به عبارت دیگر، این دستور مشخص میکند که رباتها باید چه مدت زمانی بین بررسی هر صفحه صبر کنند. اگرچه این دستور برای بینگ و Yandex هنوز معتبر است، اما گوگل دیگر از آن پشتیبانی نمیکند. استفاده از این دستور برای سایتهای بزرگ، میتواند باعث کاهش سرعت خزش شود.
User-agent: Googlebot Crawl-delay: 5
-
Noindex
دستور Noindex، برای جلوگیری از ایندکس شدن صفحات وبسایت استفاده میشود. اگرچه این دستور در گذشته مورد استفاده قرار میگرفت، اما گوگل به طور رسمی از آن پشتیبانی نمیکند. برای جلوگیری از ایندکس شدن یک صفحه، باید از تگ x-robots HTTP header استفاده کنید.
User-agent: Googlebot Noindex: /blog
-
Nofollow
دستور Nofollow، برای جلوگیری از دنبال کردن لینکهای موجود در یک صفحه استفاده میشود. گوگل به طور رسمی از این دستور نیز پشتیبانی نمیکند. برای نوفالو کردن لینکها، باید از تگ rel="nofollow" استفاده کنید.
User-agent: Googlebot Nofollow: /blog
چرا ساخت فایل Robots.txt مهم است؟
ساخت فایل robots.txt برای وبسایتهایی که تعداد صفحات زیادی دارند، ضروری است. با استفاده از این فایل، میتوانید کنترل بیشتری بر نحوه ایندکس شدن صفحات وبسایتتان داشته باشید و از این طریق، به بهبود سئو و بهینهسازی وبسایتتان کمک کنید. در اینجا، به برخی از مزایای استفاده از robots.txt اشاره میکنیم:
- جلوگیری از ایندکس شدن محتوای تکراری
- حفظ حریم خصوصی بخشهایی از وبسایت
- جلوگیری از خزش صفحات جستجوی داخلی
- بهبود عملکرد سرور و جلوگیری از بار اضافی
- بهینهسازی بودجه خزش گوگل
- جلوگیری از نمایش تصاویر و ویدیوها در نتایج جستجو (در صورت نیاز)
نکته: هیچ تضمینی وجود ندارد که صفحات مسدود شده در نتایج جستجو ظاهر نشوند، به خصوص اگر آدرس آن صفحه در وبسایتهای دیگر ذکر شده باشد.
آموزش ساخت فایل Robots.txt
اگر فایل robots.txt در وبسایت شما وجود ندارد، میتوانید آن را به راحتی ایجاد کنید. برای این کار، کافی است یک فایل متنی (.txt) ایجاد کنید و دستورات مورد نظر خود را در آن وارد کنید. سپس، فایل را با نام robots.txt ذخیره کنید. شما میتوانید از ابزارهای آنلاین برای ساخت این فایل نیز استفاده کنید. یکی از این ابزارها، tools seo book است.
اگر تجربه ساخت فایل robots.txt را ندارید، استفاده از ابزارهای آنلاین میتواند به شما کمک کند تا از اشتباهات احتمالی جلوگیری کنید.
محل قرارگیری فایل Robots.txt
فایل robots.txt باید در دایرکتوری ریشه (root directory) دامنه وبسایت شما قرار گیرد. به عنوان مثال، برای دامنه example.com، فایل robots.txt باید در آدرس example.com/robots.txt در دسترس باشد. اگر میخواهید تنظیمات را برای یک زیر دامنه (مانند blog.example.com) اعمال کنید، فایل robots.txt باید در مسیر blog.example.com/robots.txt قرار گیرد.
ویرایش فایل Robots.txt در وردپرس با افزونه
وردپرس به طور پیشفرض فایل robots.txt را ایجاد نمیکند، اما شما میتوانید به راحتی آن را ایجاد یا ویرایش کنید. یکی از سادهترین راهها، استفاده از افزونههای سئو مانند Yoast SEO است. برای ویرایش فایل robots.txt با استفاده از افزونه Yoast SEO، مراحل زیر را دنبال کنید:
- وارد پیشخوان وردپرس خود شوید.
- از منوی سمت چپ، روی گزینه “SEO” کلیک کنید.
- در زیر منوی نمایش داده شده، روی گزینه “ابزارها” (Tools) کلیک کنید.
- در صفحه ابزارها، روی گزینه “ویرایشگر پرونده” کلیک کنید.
- تغییرات مورد نظر خود را در فایل robots.txt ایجاد کنید و سپس آنها را ذخیره کنید.
ترفندهای بهینهسازی فایل Robots.txt
برای بهینهسازی فایل robots.txt و جلوگیری از بروز خطا، نکات زیر را در نظر داشته باشید:
-
هر دستور را در یک خط جداگانه بنویسید
هر دستور باید در یک خط جداگانه نوشته شود تا خوانایی فایل افزایش یابد. به عنوان مثال:
User-agent: * Disallow: /directory/ Disallow: /another-directory
-
از (*) برای کوتاه کردن دستورات استفاده کنید
برای اعمال یک دستور بر روی یک بخش کلی از وبسایت، میتوانید از علامت ستاره (*) استفاده کنید. به عنوان مثال، برای مسدود کردن دسترسی به تمام صفحات محصولات، میتوانید از کد زیر استفاده کنید:
User-agent: * Disallow: /products/*
-
استفاده از $ برای مشخص کردن انتهای URL
با استفاده از علامت $ در انتهای آدرس، میتوانید مشخص کنید که دسترسی فقط به آدرسهایی که با آن عبارت به پایان میرسند، مسدود شود. به عنوان مثال، برای مسدود کردن دسترسی به فایلهای PDF، میتوانید از کد زیر استفاده کنید:
User-agent: * Disallow: /*.pdf$
-
استفاده از یک User-agent برای هر دستور
اگر میخواهید برای یک User-agent، چند دستور تعریف کنید، نیازی به تکرار User-agent برای هر دستور نیست. این کار، خوانایی فایل را افزایش میدهد و از بروز خطاهای احتمالی جلوگیری میکند.
-
استفاده از / برای جلوگیری از مسدود شدن صفحات اشتباه
هنگام استفاده از دستور Disallow، به کاراکتر / توجه کنید. به عنوان مثال، اگر میخواهید دسترسی به پوشه /en را مسدود کنید، باید از کد زیر استفاده کنید:
User-agent: * Disallow: /en/
استفاده از / در انتهای /en، باعث میشود فقط صفحات و فایلهای داخل پوشه /en مسدود شوند و صفحات دیگر که با en شروع میشوند، تحت تأثیر قرار نگیرند.
-
استفاده از کامنت برای افزایش خوانایی
برای افزایش خوانایی فایل robots.txt، میتوانید از کامنتها (توضیحات) استفاده کنید. کامنتها با علامت # شروع میشوند و توسط رباتها نادیده گرفته میشوند. به عنوان مثال:
# این دستور، ربات بینگ را از بررسی وبسایت ما منع میکند User-agent: Bingbot Disallow: /
-
ایجاد فایل Robots.txt مجزا برای هر دامنه و زیر دامنه
اگر از چند زیر دامنه (subdomain) استفاده میکنید، باید برای هر یک از آنها یک فایل robots.txt جداگانه ایجاد کنید. به عنوان مثال، برای example.com و blog.example.com، باید دو فایل robots.txt متفاوت داشته باشید.
نمونههای کاربردی از فایل Robots.txt
در اینجا، چند نمونه از فایل robots.txt را مشاهده میکنید که میتوانید از آنها استفاده کنید:
-
اجازه دسترسی به همه رباتها به همه صفحات
User-agent: * Allow: /
-
مسدود کردن دسترسی همه رباتها به همه صفحات
User-agent: * Disallow: /
-
مسدود کردن یک پوشه خاص برای همه رباتها
User-agent: * Disallow: /folder/
-
مسدود کردن یک پوشه خاص به جز یک فایل خاص
User-agent: * Disallow: /folder/ Allow: /folder/page.html
-
مسدود کردن یک نوع فایل خاص
User-agent: * Disallow: /*.pdf$
-
مسدود کردن URL های پارامتری برای گوگل
User-agent: Googlebot Disallow: /*?
بررسی و عیبیابی فایل Robots.txt
پس از ایجاد و اعمال تغییرات در فایل robots.txt، مهم است که آن را بررسی کنید تا از صحت عملکرد آن اطمینان حاصل کنید. برای این کار، میتوانید از ابزارهای Google Search Console استفاده کنید. در بخش «Coverage» در Google Search Console، میتوانید خطاهای مربوط به فایل robots.txt را مشاهده و بررسی کنید. در اینجا، به بررسی برخی از خطاهای رایج و راهحلهای آنها میپردازیم:
-
مسدود شدن دسترسی به یک URL خاص
این مشکل زمانی رخ میدهد که یک URL مهم در نقشه سایت شما، توسط دستورات robots.txt مسدود شده باشد. برای رفع این مشکل، باید وارد ابزار Google Search Console شوید و با استفاده از ابزار بررسی URL، دستورات robots.txt مربوط به آن صفحه را بررسی کنید. در صورت نیاز، دستورات مربوطه را اصلاح کنید.
-
پیام “Blocked by robots.txt”
این پیام نشان میدهد که محتوای یک صفحه، توسط فایل robots.txt مسدود شده و در حال حاضر ایندکس نشده است. اگر این محتوا برای شما مهم است، باید دستورات مربوط به آن را در فایل robots.txt حذف کنید. همچنین، اطمینان حاصل کنید که صفحه مورد نظر، تگ noindex را ندارد.
-
پیام “Indexed, though blocked by robots.txt”
این پیام نشان میدهد که صفحاتی که توسط robots.txt مسدود شدهاند، ایندکس شدهاند. این اتفاق، معمولاً زمانی رخ میدهد که صفحه توسط لینکهایی از وبسایتهای دیگر، در معرض دید گوگل قرار گرفته باشد. اگر میخواهید یک صفحه از نتایج جستجو حذف شود، استفاده از robots.txt راهحل مناسبی نیست. در این شرایط، بهتر است از تگ noindex در بخش head صفحه استفاده کنید.
مزایای کلیدی استفاده از Robots.txt
استفاده صحیح از فایل robots.txt، مزایای متعددی برای وبسایت شما دارد:
-
بهینهسازی مصرف پهنای باند و منابع سرور
با محدود کردن دسترسی رباتها به صفحات غیرضروری، میتوانید مصرف پهنای باند و منابع سرور را بهینه کنید. این کار، به بهبود سرعت وبسایت و تجربه کاربری کمک میکند.
بهبود مدیریت بودجه خزش (Crawl Budget)
با هدایت رباتها به صفحات مهم و حذف صفحات غیرضروری، میتوانید بودجه خزش گوگل را بهینه کنید. این کار، باعث میشود که رباتها زمان بیشتری را صرف بررسی صفحات مهم وبسایت شما کنند.
اگرچه، فایل robots.txt ابزار قدرتمندی برای سئو است، اما باید با دقت و دانش کافی از آن استفاده کنید. اشتباهات در این فایل، میتواند به مشکلات جدی در سئو وبسایت شما منجر شود. بنابراین، اگر در این زمینه تجربه کافی ندارید، توصیه میشود از یک متخصص سئو کمک بگیرید.
با بهکارگیری نکات و ترفندهای ارائه شده در این مقاله، میتوانید فایل robots.txt را به درستی ایجاد و بهینهسازی کنید و به بهبود سئو وبسایت خود کمک کنید.